サンプルサイズの決め方
間違いも含まれている可能性はあるが、現状の理解をまとめる。
「サンプルサイズ」は、「有意水準」と「検出力」と「効果量」の値が決まれば、決まる。
この4つの因子は、いずれが3つの値が決まると、残りの1つの因子の値が決まる関係にある。
「有意水準」と「検出力」と「効果量」それぞれについての説明
「有意水準」
本当は帰無仮説が正しいのに、誤って棄却してしまう確率。
図中の"False Negative"
0.01や0.05を使うことが多い。
「検出力」
帰無仮説が正しくないときに、正しくを棄却する確率。
図中の"True Negative"
0.8を使うことが多い。
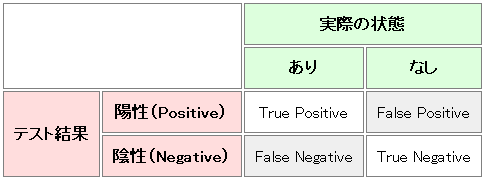
http://mojix.org/2008/11/24/false_positive_false_negativeより
「効果量」
効果量は「検出したい差の程度」や「変数間の関係の強さ」のことで、その実験の効果を見るための指標。
P値はその値より極端な値をとる確率を示したものに過ぎないため、その実験において実際にどの程度の効果があったかを知ることはできない。
例えば同じ平均値の2群を比較した場合にはサンプルサイズが大きい方がP値は小さくなる。
概念は、上記でよいのだが、具体的な問題を考えたとき、それぞれの値をどう導出するのかがまだ理解できていない。
以下、参考サイト
※具体的な問題には下サイトが参考になりそう。しかし、4つの因子との関係が明らかではない。
標本の大きさの決定
※主に参考にしたサイト
https://bellcurve.jp/statistics/course/9313.html
※Rのコードが載っているので実践的
https://www.slideshare.net/takashijozaki1/tokyo-r140222-tjo
※本来参考にすべき本
")
Google Cloudで追加ディスクのマウントを行う
以下の2ステップに分かれる。
1.google cloud上でディスクの追加を行う。
2.OS上で追加ディスクのマウントの設定を行う。
1.google cloud上でディスクの追加を行う。
ここではgoogle cloudのコンソール上での操作を行う。
対象のインスタンス→編集→追加ディスク→項目を追加

ディスクの作成を行いソースの種類をなしにして、作成する。
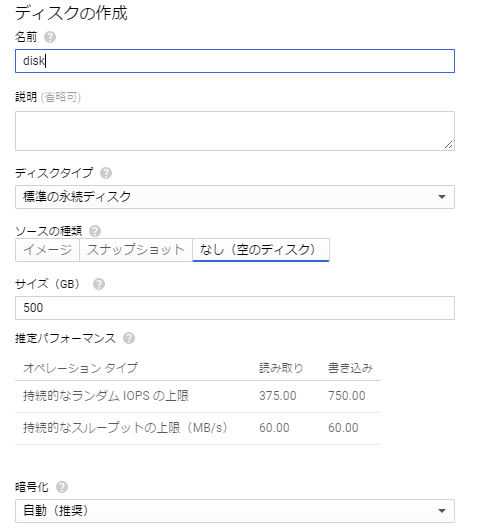
これでディスクの追加は完了
2.OS上で追加ディスクのマウントの設定を行う。
ここからはGoogle CloudというよりOSの問題
OSは今回centos7を利用
※windowsであれば、[ スタート] - [ 管理ツール ] – [サーバーマネージャー] で追加する
http://www.cloudn-service.com/guide/manuals/html/vpcopennw/rsts/ManageDisks/mount_disks_win.html
2-1.マウントの準備
ディスクをフォーマットする
sudo mkfs.ext4 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/disk/by-id/google-disk
マウントポイントの作成
sudo mkdir -p /mnt/disks/extend
マウントしてみる
sudo mount -o defaults /dev/disk/by-id/google-disk /mnt/disks/extend
マウントされているディスクを表示し、一覧に含まれていれば正しくできている
df -h
2-2.起動時にマウントする設定
sudo vi /etc/fstab
でファイルを開き、下の行を末尾に追記する
/dev/disk/by-id/google-disk /mnt/disks/extend ext4 defaults 0 2
各項目の意味はこちらを参照
www.infraeye.com
参考:
http://www.apps-gcp.com/gce-disk-expansion/
Linux ハードディスクをマウント(mount)する
Google CloudにSCP・SSH・SFTPでアクセス
環境はWindows
SCP・SSH・SFTPいずれにおいても必要なのは以下の4つ、
- ユーザID
- アクセス先IP
- パスワード
- 秘密鍵
接続自体はクライアントソフトの違いくらいで問題なのは公開鍵・秘密鍵の生成と、Google Cloudへ公開鍵の登録
操作は公式で用意しているので省略。
https://cloud.google.com/compute/docs/instances/connecting-to-instance?hl=ja
PuTTYで鍵を生成する場合、必要な4つのうちアクセス先以外はこの時に決定される。
実際のアクセス方法についてもWinSCPでの例が公式で記載されている。
https://cloud.google.com/compute/docs/instances/transfer-files?hl=ja
jupyter, AnacondaをGoogle Cloud Platfrom上で動かす
jupyterをGoogle Cloud Platfrom上で動かして、ローカルのブラウザからアクセスしたい。
以下その手順
1.Google Cloud Platfromでインスタンス作成

環境構築時は小さい構成でよい。
今回はcentOSを利用している。
できたらSSHでアクセスする。
2.Anacondaインストール
2-1. wget,bzip2のインストール
su yum install wget su yum install bzip2
2-2. Anacondaのダウンロードとインストール
(最新のバージョンはhttps://www.continuum.io/downloadsで確認)
mkdir downloads cd downloads wget https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh bash Anaconda3-4.3.1-Linux-x86_64.sh
途中出てくる質問はすべてyesにする。
3.jupyterの設定
3-1. コンフィギュレーションファイルを作成
cd jupyter notebook --generate-config cd .jupyter
3-2. SSL用の鍵を作成
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mykey.key -out mycert.pem
3-3. パスワードからハッシュ値の生成
pythonで以下を実行、得られたハッシュ値は控えておく。
from notebook.auth import passwd; passwd()
3-4. コンフィギュレーションファイルを編集
# OpenSSLで作ったファイルへのパス c.NotebookApp.certfile = u'/home/username/.jupyter/mycert.pem' c.NotebookApp.keyfile = u'/home/username/.jupyter/mykey.key' # どのIPアドレスからのアクセスも受け入れる c.NotebookApp.ip = '*' # passwd()コマンドで作ったパスワードのハッシュを貼る c.NotebookApp.password = u'sha1:bcd259ccf...' # 勝手にブラウザを起動しない c.NotebookApp.open_browser = False # 外部からアクセスするためのポート番号を指定する c.NotebookApp.port = 8888
3-5. 作業フォルダの作成とjupyterの起動
cd mkdir jupyter_workdir cd jupyter_workdir jupyter notebook

4-1. ファイアウォールのHTTPS トラフィックを許可するにチェックを入れる
4-2. 外部IPで新しい静的IPを追加する(IP追加にコスト発生の場合あり)
4-3. ネットワークのdefaultをクリックし、ファイアウォール ルールを追加
名前:任意
ソースタグ: 0.0.0.0/0 どのようなホストからでも接続を許す
許可対象のプロトコルまたはポート : tcp:8888

変更出来たら設定を保存する
確認
https://「外部IP」:8888/ にアクセスし、先ほど作成したパスワードを入力する。

実行できた。

参考
Set up Anaconda + IPython + Tensorflow + Julia on a Google Compute Engine VM – Harold Soh
Google Cloud Platform で Jupyter のサービスを動かす » DSP空挺団
MySQL:エラー:The total number of locks exceeds the lock table size
上記のエラーが出た場合'innodb_buffer_pool_size'の割り当てを大きくすることで対応可能とのこと。
If you had the error, you can get correct work by assign more memory to 'innodb_buffer_pool_size'.
MySQL:エラー:The total number of locks exceeds the lock table size | 猫型iPS細胞研究所
対応1.デフォルトを変更 change the default.
永続的に変更したい場合は、my.cnfを変更することで対応可能。今回は扱わない。
If you want to change eternal, you should edit 'my.cnf'. I don,t handle it this time.
日々の覚書: my.cnfのパラメータ優先順位
対応2.セッション中のみ変更 ←今回 change during session.
結論としては以下で変更可能。can change by follow code.
SET GLOBAL innodb_buffer_pool_size = 変更したいサイズ;
ただし、バッファープールは内部的に複数の領域(インスタンス)に分割されている。
SHOW VARIABLES LIKE "innodb_%_size";
で表示されるinnodb_buffer_pool_instastancesの倍数で設定しないとエラーが出る。
'innodb_buffer_pool_size' should set multiple 'innodb_buffer_pool_instastances'
Anaconda環境でTensorFlowをインストール Installing TensorFlow with Anaconda.
環境構築手順を整理しておこうと思ったが、
公式に素晴らしいチュートリアルがあるのでそれを実行し、補足点を記述する。
目次
1.インストール
2.チュートリアル
3.途中詰まったところ
1.インストール
ここ参照:https://www.tensorflow.org/install/install_windows
今回の目的はwindows上かつ、anacondaだが、他環境のものもある。
Installing TensorFlow | TensorFlow
CPU support only.とGPU supportとがあるが、GPUを利用したい場合でもまず前者をインストールしてみなさいとの記述がある。
環境を別で作って、アクティベートして、pipでインストールする。
C:> conda create -n tensorflow C:> activate tensorflow (tensorflow)C:> pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.0.1-cp35-cp35m-win_amd64.whl
2.チュートリアル
チュートリアル上のコードをそのまま実行しただけだが、以下のコード
https://www.tensorflow.org/get_started/mnist/beginners
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) import tensorflow as tf x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None, 10]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.InteractiveSession() tf.global_variables_initializer().run() for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
3.途中詰まったところ
途中同じコードを実行しているはずなのに下図のエラーが出たりでなかったりがあった。
原因は未特定だが、"unknown op"とあるので、対象のopが読み込まれていない可能性がある。
なのでimport tensorflow as tf でもう一度ライブラリをインポートしなおすと直るかもしれない。

python:Anacondaでpython2,python3環境を併存・共存させる Build environment of python2 and python3 on Anaconda.
以下はwindows環境で行っている。
anacondaはインストール済みとする。
This is windows environment.
Package of anaconda is already installed.
python2,python3の環境名をそれぞれpy2,py3として作成する。
Create environment names of python2 and python3 as py2 and "py3".
C:\>conda create -n py2 python=2.7 anaconda
C:\>conda create -n py3 python=3.5 anaconda
存在している環境の一覧を表示する、*がついている環境が現状選択されている
View all existing environment. Environment marked "*" is selected.
C:\>conda info -e # conda environments: # py2 C:Anaconda3\envs\py2 py3 C:Anaconda3\envs\py2 root * C:Anaconda3
特定の環境をアクティベートする
Activate environment "py2".
C:\activate py2
成功すると先頭に環境名が表示されるようになる
If activate is success, the environment name on top.
(py2)C:\
※注意点
windowsのpathの設定は切り替え時に変更されない為、外部開発環境などからそのままpythonを実行した場合デフォルトの環境で実行される。
デフォルトの環境以外で実行したい場合は、その前に環境の切り替えを行う必要がある。
Due to path setting is not change when activate, it is run that default environment via other development environment tools.
If you want to run on any other environment, you have to activate the environment.